年轻人不讲武德
相信很多朋友都有这种苦恼:自己的文章被搬运了!

你上午在博客园、CSDN、知乎、简书等平台发布的文章,下午去百度搜索出来一大堆一模一样的内容出来
有武德的给你【标明出处】(标明文章来自哪儿,附上链接),没武德的不仅没标明出处,他还自己表示为原创(内心一万头草泥马在奔腾~)。
文章搬运我个人是欢迎的,但是需要注明出处。对于这种情况很难说,褒贬不一,个人看法不同,
对于我来说,肯定是想要更多人看到我的文章啦(内心窃喜~)。
比如下图左边第一个是我2019年2月份发布的一篇文章到现在为止搬运次数超过50+了(能被别人搬运也是对自己的一种肯定),
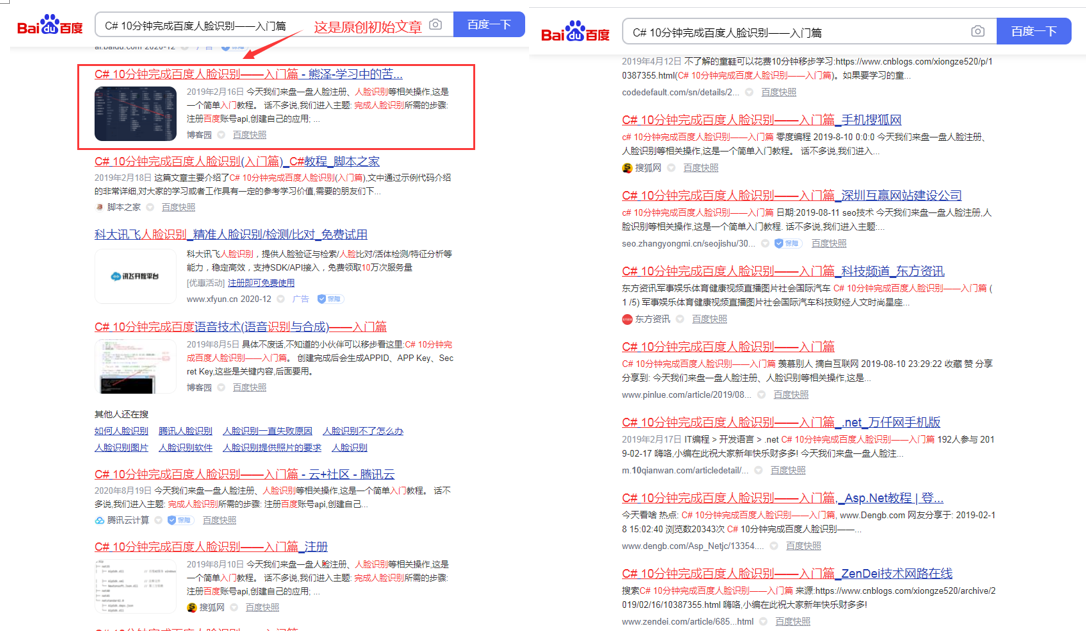
释语
对于外行的朋友来说,感觉云里雾里的,不明觉厉。
对于内行的朋友来说,就是一个简单的爬虫,获取到网页内容后重新发布一下而已。
什么是数据采集?
数据采集(也称为网络数据提取或网页爬取)是指从网上获取数据,并将获取到的数据转化为结构化的数据,最终可以将数据存储到本地计算机或数据库的一种技术。
什么是网络爬虫?
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫的分类
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:
- 通用网络爬虫(General Purpose Web Crawler)、
- 聚焦网络爬虫(Focused Web Crawler)、
- 增量式网络爬虫(Incremental Web Crawler)、
- 深层网络爬虫(Deep Web Crawler)。
实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
专业介绍:百度百科。
爬虫步骤
- 指定url;
- 基于request模块发起请求;
- 获取响应对象返回的数据;
- 解析返回的数据(正则解析、Xpath解析、BeautifulSoup解析等);
- 数据持久化存储;
接下来我们结合理论进行一下操作,以获取博客园文章为例,这里使用正则解析。
实例操作(采集博客园文章:指定链接采集)
开发环境
操作系统:windows7 x64;
开发工具:Visual Studio 2017
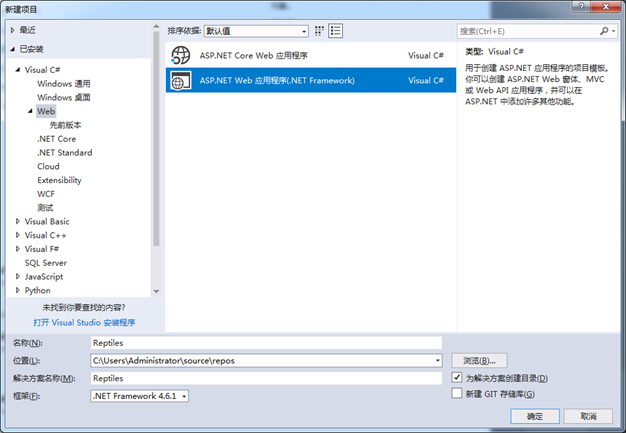
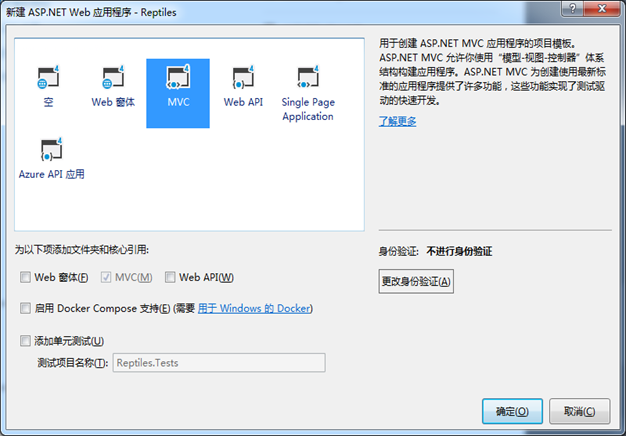
项目名称:ASP.NET Web 应用程序(.Net Framework)
数据库:SqlServer2012
实例分析
1、建立一个ASP.NET Web 应用程序项目,命名为Reptiles。
项目创建成功后,我们先去分析一下数据结构,可以根据request返回的请求分析,但是我这里的目标是html页面,所以直接F12进行分析,
我们分析后找到文章标题,文章内容,分别如下:
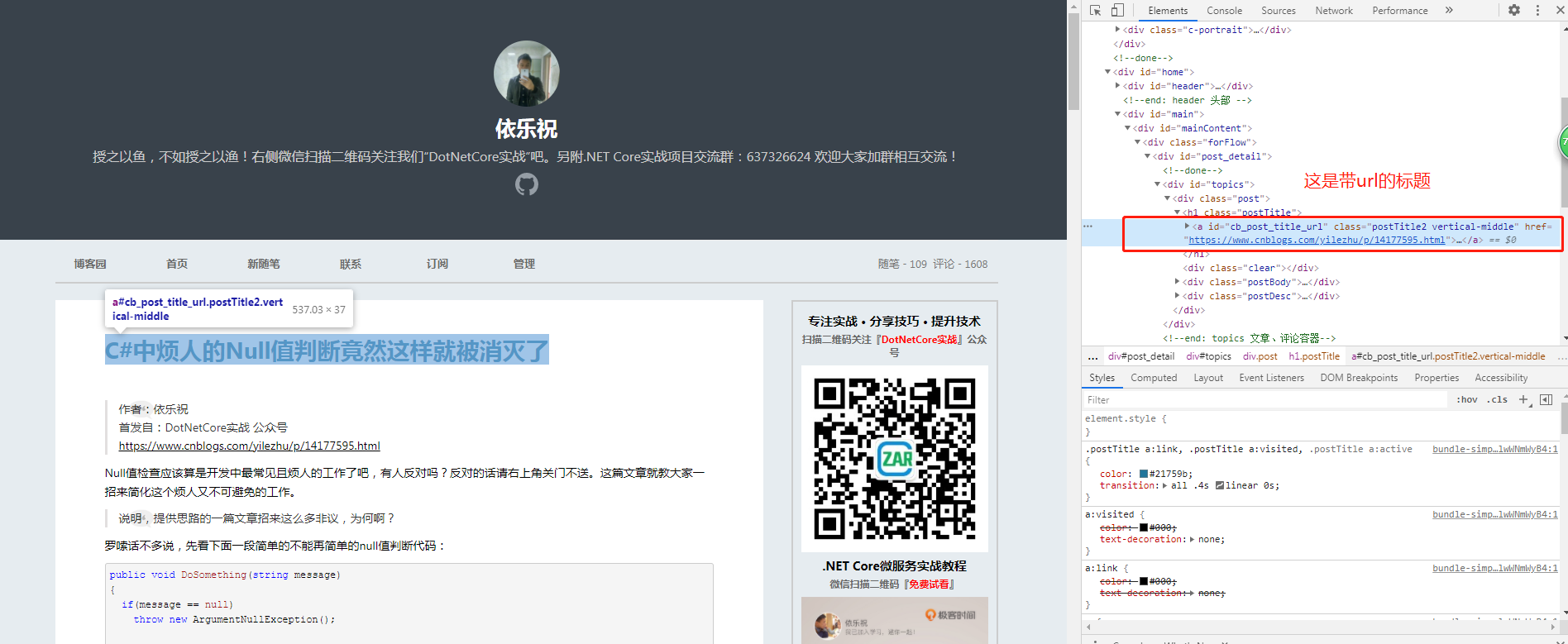
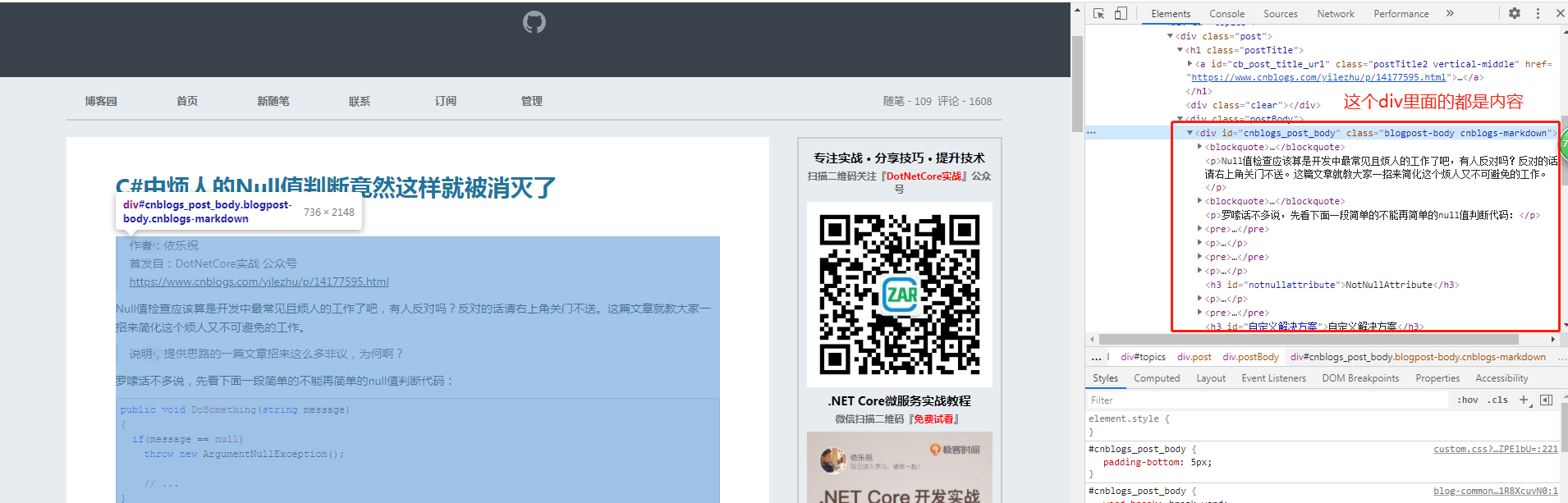
通过上面的分析,就可以先写出正则表达式:
//文章标题
Regex regTitle = new Regex(@"<a\sid=""cb_post_title_url""[^>]*?>(.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//文章内容
Regex regContent = new Regex(@"<div\sid=""cnblogs_post_body""[^>]*?>(.*?)</div>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
完整代码放在最后面,直接拷贝就可以使用;
查看一下运行结果:
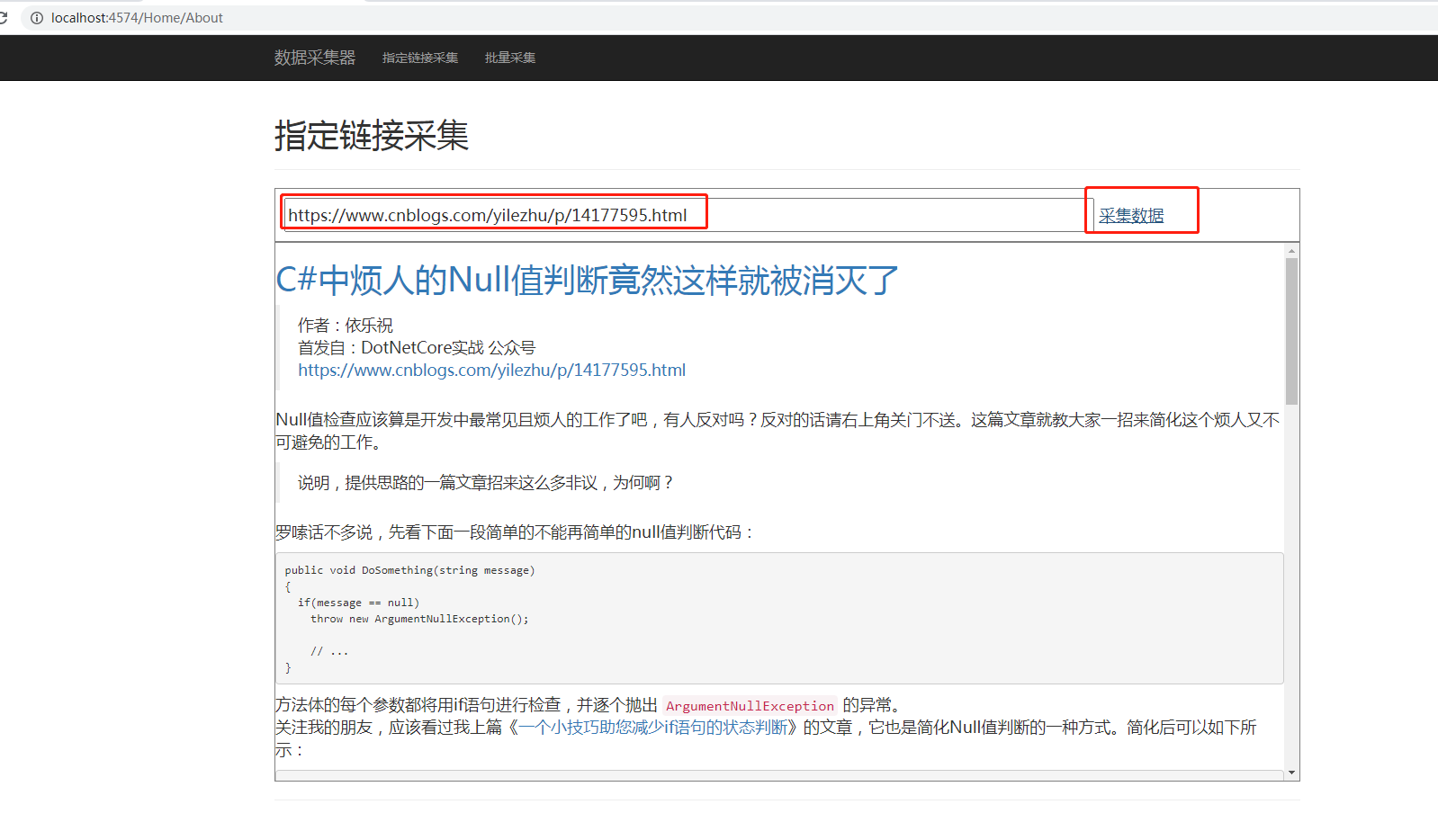
注意,这里没有持久化入库,有需要的同学根据自己的需要自行入库即可。
实例操作(采集博客园文章:批量采集)
批量采集和指定url采集差不多,批量采集需要先获取指定页面(这里以博客园首页为例),
获取页面上面的url去获取下面的内容。同样的,我们先分析一下页面数据结构,如下:
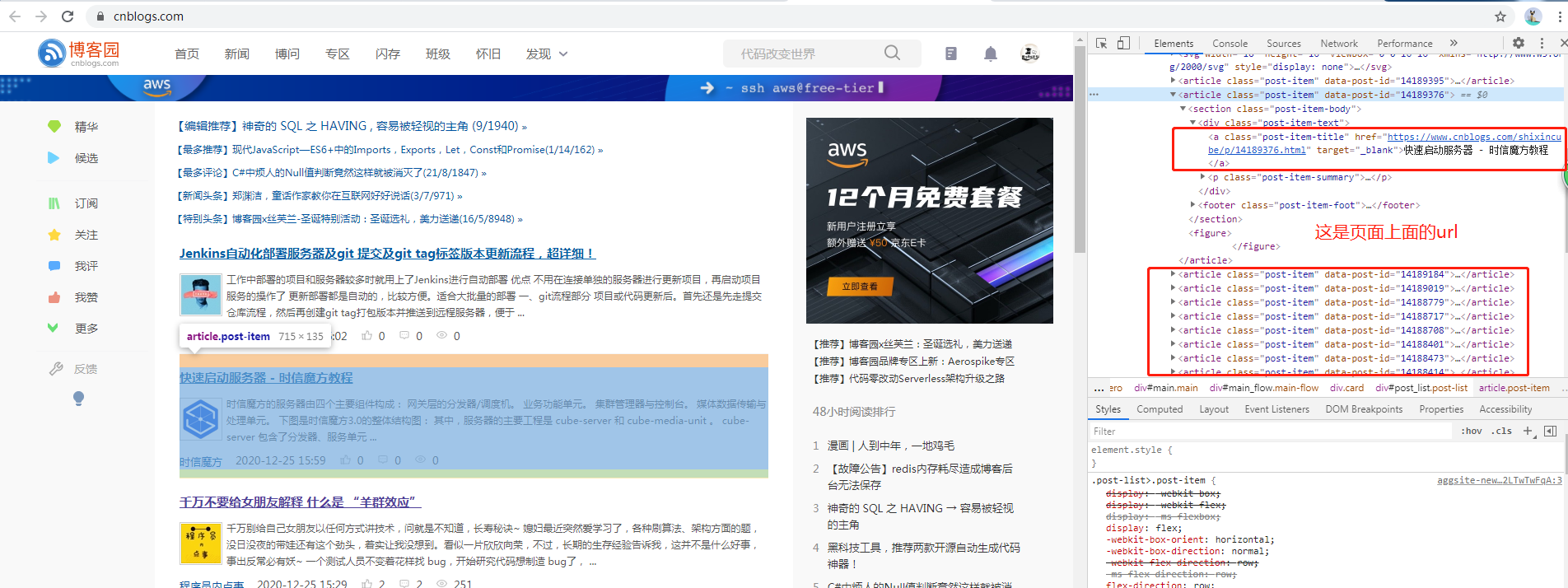
通过上面的分析,就可以先写出正则表达式:
//标题div
Regex regBody = new Regex(@"<div\spost-item-text"">([\s\S].*?)</div>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//a标签 文章标题
Regex regTitle = new Regex("<a[^>]*?>(.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//文章标题URL
string regURL = @"(?is)<a[^>]*?href=(['""\s]?)(?<href>[^'""\s]*)\1[^>]*?>";
代码放后面,我们先看一下运行结果:
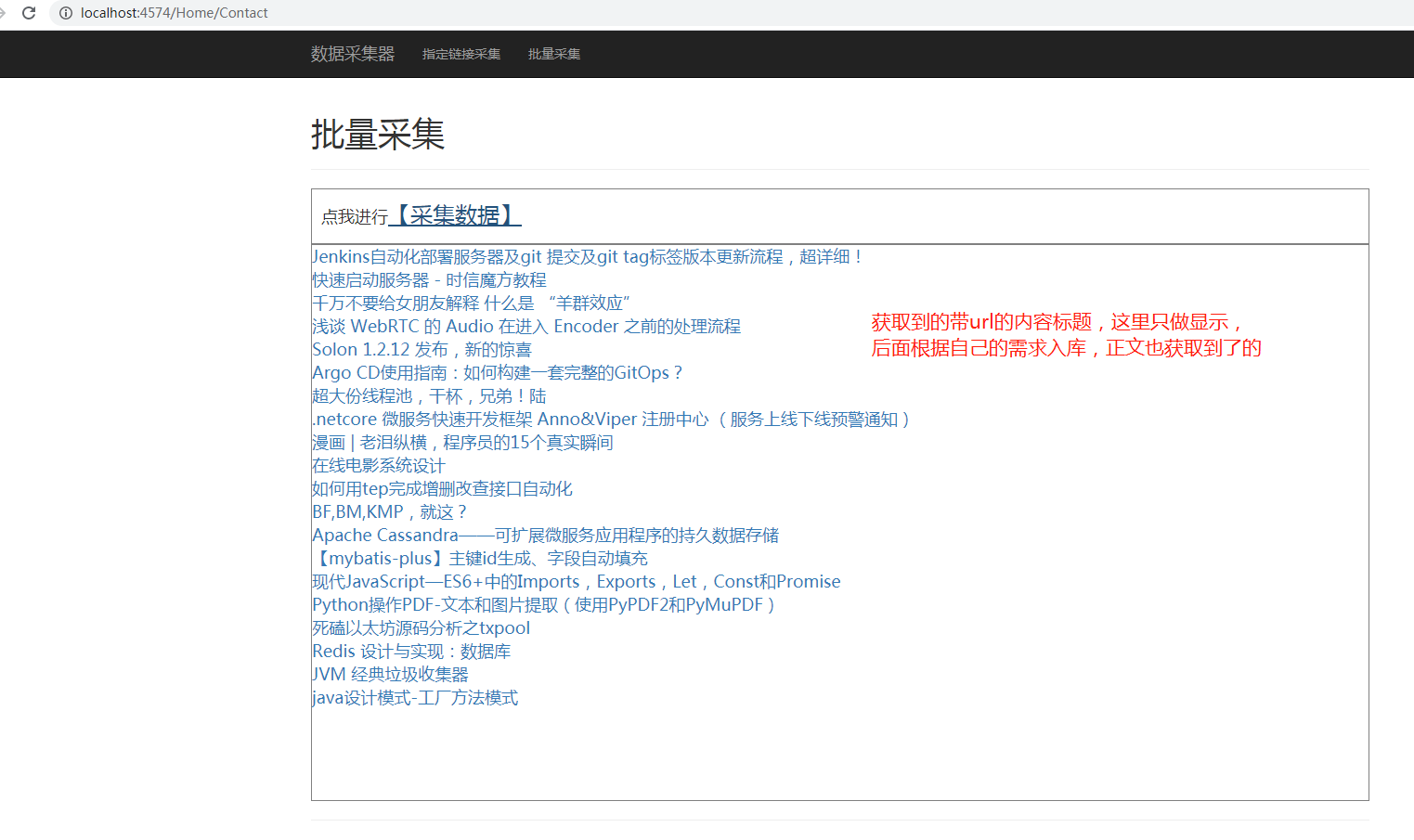
代码展示
注:建立好相应的控制器和view视图后,直接拷贝即可使用
- 批量采集视图:About
- 指定链接采集视图:Contact
- 控制器:HomeController
【 指定链接采集】前端代码
<!--这个jQuery可以引用一个在线的使用,我这里是本地的--><script src="~/Scripts/jquery-3.3.1.min.js"></script><div style="margin-top:40px;font-family:'Microsoft YaHei';font-size:18px; "> <h1>指定链接采集</h1> <hr /> <div style="height:60px;width:100%;border:1px solid gray;padding:10px"> <input style="width:900px;height:100%;max-width:900px;" id="Url" placeholder="这里是文章URL链接" /> <a href="javascript:void(0)" onclick="GetHtml()">采集数据</a> </div> <div id="content" style="overflow:auto;height:600px;width:100%;border:1px solid gray;"> <!--标题--> <h1 class="postTitle"></h1> <div class="postBody"></div> <!--内容--> </div></div><script> function GetHtml() { $.ajax({ url: "/Home/GetHtml", data: { Url: $("#Url").val() }, type: "POST", dataType: "json", success: function (data) { var data = eval("(" + data + ")"); if (data.length > 0) { $(".postTitle").html(data[0].ArticleTitle); $(".postBody").html(data[0].ArticleContent); } } }); }</script>【 批量采集】前端代码
<!--这个jQuery可以引用一个在线的使用,我这里是本地的--><script src="~/Scripts/jquery-3.3.1.min.js"></script><div style="margin-top:40px;font-family:'Microsoft YaHei';font-size:18px; "> <h1>批量采集</h1> <hr /> <div style="height:60px;width:100%;border:1px solid gray;padding:10px"> 点我进行<a href="javascript:void(0)" style="font-size:24px;" onclick="GetHtml()">【采集数据】</a> </div> <div id="content" style="overflow:auto;height:600px;width:100%;border:1px solid gray;"> <!--标题--> <div id="post_list"></div> </div></div><script> function GetHtml() { $.ajax({ url: "/Home/GetHtml", data: { Url: $("#Url").val() }, type: "POST", dataType: "json", success: function (data) { var data = eval("(" + data + ")"); if (data.length > 0) { var html_text = ""; for (var i = 0; i < data.length; i++) { html_text += '<div >' + data[i].ArticleTitle2+'</div>'; } $("#post_list").html(html_text); } } }); }</script>
控制器后端代码:
using System;using System.Collections.Generic;using System.IO;using System.Linq;using System.Net;using System.Text;using System.Text.RegularExpressions;using System.Web;using System.Web.Mvc;namespace Reptiles.Controllers{ public class HomeController : Controller { public ActionResult Index() { return View(); } public ActionResult About() { ViewBag.Message = "Your application description page."; return View(); } public ActionResult Contact() { ViewBag.Message = "Your contact page."; return View(); } //数据采集 public JsonResult GetHtml(string Url) { CnblogsModel result = new CnblogsModel(); List<CnblogsModel> HttpGetHtml = new List<CnblogsModel>(); if (string.IsNullOrEmpty(Url)) HttpGetHtml = GetUrl(); else HttpGetHtml = GetUrl(Url); var strList=Newtonsoft.Json.JsonConvert.SerializeObject(HttpGetHtml); return Json(strList, JsonRequestBehavior.AllowGet); } #region 爬虫 #region 批量采集 //得到首页的URL public static List<CnblogsModel> GetUrl() { HttpWebRequest request = (HttpWebRequest)WebRequest.Create("https://www.cnblogs.com/"); request.Method = "GET"; request.Accept = "text/html,application/xhtml+"; request.UserAgent = " Mozilla/5.0 (Windows NT 6.1; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0"; HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream stream = response.GetResponseStream(); StreamReader sr = new StreamReader(stream); string articleContent = sr.ReadToEnd(); List<CnblogsModel> list = new List<CnblogsModel>(); #region 正则表达式 //标题div Regex regBody = new Regex(@"<div\spost-item-text"">([\s\S].*?)</div>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace); //a标签 文章标题 Regex regTitle = new Regex("<a[^>]*?>(.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace); //文章标题URL string regURL = @"(?is)<a[^>]*?href=(['""\s]?)(?<href>[^'""\s]*)\1[^>]*?>";
No comments:
Post a Comment